Behind the scenes¶
Unlike many revision control systems, the concepts upon which Mercurial is built are simple enough that it's easy to understand how the software really works. Knowing these details certainly isn't necessary, so it is certainly safe to skip this chapter. However, I think you will get more out of the software with a “mental model” of what's going on.
Being able to understand what's going on behind the scenes gives me confidence that Mercurial has been carefully designed to be both safe and efficient. And just as importantly, if it's easy for me to retain a good idea of what the software is doing when I perform a revision control task, I'm less likely to be surprised by its behavior.
In this chapter, we'll initially cover the core concepts behind Mercurial's design, then continue to discuss some of the interesting details of its implementation.
Mercurial's historical record¶
Tracking the history of a single file¶
When Mercurial tracks modifications to a file, it stores the history of that file in a metadata object called a filelog. Each entry in the filelog
contains enough information to reconstruct one revision of the file that is being tracked. Filelogs are stored as files in the .hg/store/data
directory. A filelog contains two kinds of information: revision data, and an index to help Mercurial to find a revision efficiently.
A file that is large, or has a lot of history, has its filelog stored in separate data (“.d” suffix) and index (“.i” suffix) files. For small
files without much history, the revision data and index are combined in a single “.i” file. The correspondence between a file in the working
directory and the filelog that tracks its history in the repository is illustrated in fig:concepts:filelog.
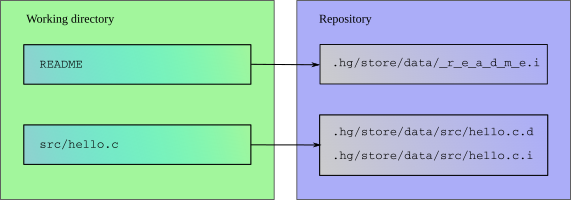
Relationships between files in working directory and filelogs in repository
Managing tracked files¶
Mercurial uses a structure called a manifest to collect together information about the files that it tracks. Each entry in the manifest contains information about the files present in a single changeset. An entry records which files are present in the changeset, the revision of each file, and a few other pieces of file metadata.
Recording changeset information¶
The changelog contains information about each changeset. Each revision records who committed a change, the changeset comment, other pieces of changeset-related information, and the revision of the manifest to use.
Relationships between revisions¶
Within a changelog, a manifest, or a filelog, each revision stores a pointer to its immediate parent (or to its two parents, if it's a merge revision). As I mentioned above, there are also relationships between revisions across these structures, and they are hierarchical in nature.
For every changeset in a repository, there is exactly one revision stored in the changelog. Each revision of the changelog contains a pointer to a single revision of the manifest. A revision of the manifest stores a pointer to a single revision of each filelog tracked when that changeset was created. These relationships are illustrated in fig:concepts:metadata.
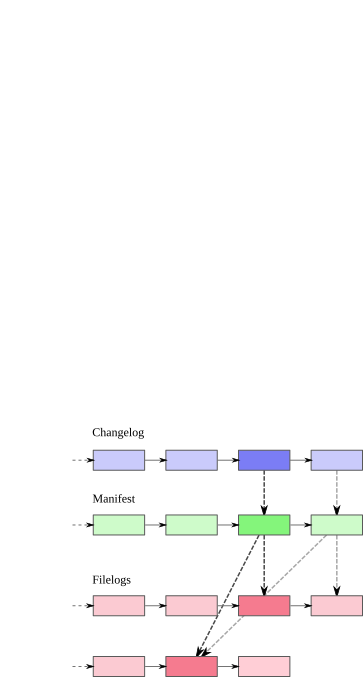
Metadata relationships
As the illustration shows, there is not a “one to one” relationship between revisions in the changelog, manifest, or filelog. If a file that Mercurial tracks hasn't changed between two changesets, the entry for that file in the two revisions of the manifest will point to the same revision of its filelog [1].
Safe, efficient storage¶
The underpinnings of changelogs, manifests, and filelogs are provided by a single structure called the revlog.
Efficient storage¶
The revlog provides efficient storage of revisions using a delta mechanism. Instead of storing a complete copy of a file for each revision, it stores the changes needed to transform an older revision into the new revision. For many kinds of file data, these deltas are typically a fraction of a percent of the size of a full copy of a file.
Some obsolete revision control systems can only work with deltas of text files. They must either store binary files as complete snapshots or encoded into a text representation, both of which are wasteful approaches. Mercurial can efficiently handle deltas of files with arbitrary binary contents; it doesn't need to treat text as special.
Safe operation¶
Mercurial only ever appends data to the end of a revlog file. It never modifies a section of a file after it has written it. This is both more robust and efficient than schemes that need to modify or rewrite data.
In addition, Mercurial treats every write as part of a transaction that can span a number of files. A transaction is atomic: either the entire transaction succeeds and its effects are all visible to readers in one go, or the whole thing is undone. This guarantee of atomicity means that if you're running two copies of Mercurial, where one is reading data and one is writing it, the reader will never see a partially written result that might confuse it.
The fact that Mercurial only appends to files makes it easier to provide this transactional guarantee. The easier it is to do stuff like this, the more confident you should be that it's done correctly.
Fast retrieval¶
Mercurial cleverly avoids a pitfall common to all earlier revision control systems: the problem of inefficient retrieval. Most revision control systems store the contents of a revision as an incremental series of modifications against a “snapshot”. (Some base the snapshot on the oldest revision, others on the newest.) To reconstruct a specific revision, you must first read the snapshot, and then every one of the revisions between the snapshot and your target revision. The more history that a file accumulates, the more revisions you must read, hence the longer it takes to reconstruct a particular revision.
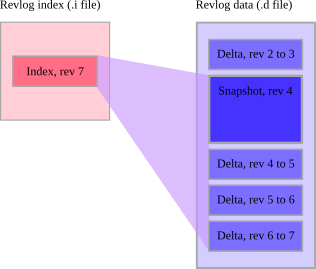
Snapshot of a revlog, with incremental deltas
The innovation that Mercurial applies to this problem is simple but effective. Once the cumulative amount of delta information stored since the last snapshot exceeds a fixed threshold, it stores a new snapshot (compressed, of course), instead of another delta. This makes it possible to reconstruct any revision of a file quickly. This approach works so well that it has since been copied by several other revision control systems.
fig:concepts:snapshot illustrates the idea. In an entry in a revlog's index file, Mercurial stores the range of entries from the data file that it must read to reconstruct a particular revision.
Aside: the influence of video compression¶
If you're familiar with video compression or have ever watched a TV feed through a digital cable or satellite service, you may know that most video compression schemes store each frame of video as a delta against its predecessor frame.
Mercurial borrows this idea to make it possible to reconstruct a revision from a snapshot and a small number of deltas.
Identification and strong integrity¶
Along with delta or snapshot information, a revlog entry contains a cryptographic hash of the data that it represents. This makes it difficult to forge the contents of a revision, and easy to detect accidental corruption.
Hashes provide more than a mere check against corruption; they are used as the identifiers for revisions. The changeset identification hashes that you see as an end user are from revisions of the changelog. Although filelogs and the manifest also use hashes, Mercurial only uses these behind the scenes.
Mercurial verifies that hashes are correct when it retrieves file revisions and when it pulls changes from another repository. If it encounters an integrity problem, it will complain and stop whatever it's doing.
In addition to the effect it has on retrieval efficiency, Mercurial's use of periodic snapshots makes it more robust against partial data corruption. If a revlog becomes partly corrupted due to a hardware error or system bug, it's often possible to reconstruct some or most revisions from the uncorrupted sections of the revlog, both before and after the corrupted section. This would not be possible with a delta-only storage model.
Revision history, branching, and merging¶
Every entry in a Mercurial revlog knows the identity of its immediate ancestor revision, usually referred to as its parent. In fact, a revision contains room for not one parent, but two. Mercurial uses a special hash, called the “null ID”, to represent the idea “there is no parent here”. This hash is simply a string of zeroes.
In fig:concepts:revlog, you can see an example of the conceptual structure of a revlog. Filelogs, manifests, and changelogs all have this same structure; they differ only in the kind of data stored in each delta or snapshot.
The first revision in a revlog (at the bottom of the image) has the null ID in both of its parent slots. For a “normal” revision, its first parent slot contains the ID of its parent revision, and its second contains the null ID, indicating that the revision has only one real parent. Any two revisions that have the same parent ID are branches. A revision that represents a merge between branches has two normal revision IDs in its parent slots.
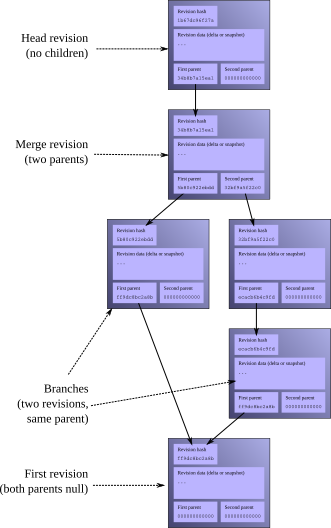
The conceptual structure of a revlog
The working directory¶
In the working directory, Mercurial stores a snapshot of the files from the repository as of a particular changeset.
The working directory “knows” which changeset it contains. When you update the working directory to contain a particular changeset, Mercurial looks up the appropriate revision of the manifest to find out which files it was tracking at the time that changeset was committed, and which revision of each file was then current. It then recreates a copy of each of those files, with the same contents it had when the changeset was committed.
The dirstate is a special structure that contains Mercurial's knowledge of the working directory. It is maintained as a file named .hg/dirstate
inside a repository. The dirstate details which changeset the working directory is updated to, and all of the files that Mercurial is tracking in the
working directory. It also lets Mercurial quickly notice changed files, by recording their checkout times and sizes.
Just as a revision of a revlog has room for two parents, so that it can represent either a normal revision (with one parent) or a merge of two earlier
revisions, the dirstate has slots for two parents. When you use the hg update command, the changeset that you update to is stored in the “first parent” slot, and the null ID in the second. When you hg merge with another changeset, the first parent remains unchanged, and the second parent is filled in with the changeset you're merging with. The
hg parents command tells you what the parents of the dirstate are.
What happens when you commit¶
The dirstate stores parent information for more than just book-keeping purposes. Mercurial uses the parents of the dirstate as the parents of a new changeset when you perform a commit.

The working directory can have two parents
fig:concepts:wdir shows the normal state of the working directory, where it has a single changeset as parent. That changeset is the tip, the newest changeset in the repository that has no children.
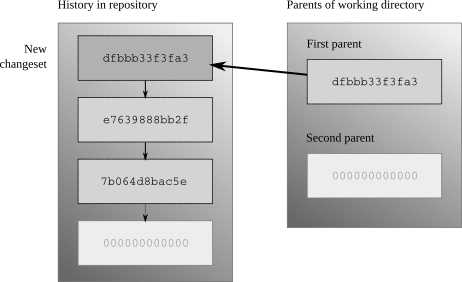
The working directory gains new parents after a commit
It's useful to think of the working directory as “the changeset I'm about to commit”. Any files that you tell Mercurial that you've added, removed, renamed, or copied will be reflected in that changeset, as will modifications to any files that Mercurial is already tracking; the new changeset will have the parents of the working directory as its parents.
After a commit, Mercurial will update the parents of the working directory, so that the first parent is the ID of the new changeset, and the second is the null ID. This is shown in fig:concepts:wdir-after-commit. Mercurial doesn't touch any of the files in the working directory when you commit; it just modifies the dirstate to note its new parents.
Creating a new head¶
It's perfectly normal to update the working directory to a changeset other than the current tip. For example, you might want to know what your project looked like last Tuesday, or you could be looking through changesets to see which one introduced a bug. In cases like this, the natural thing to do is update the working directory to the changeset you're interested in, and then examine the files in the working directory directly to see their contents as they were when you committed that changeset. The effect of this is shown in fig:concepts:wdir-pre-branch.
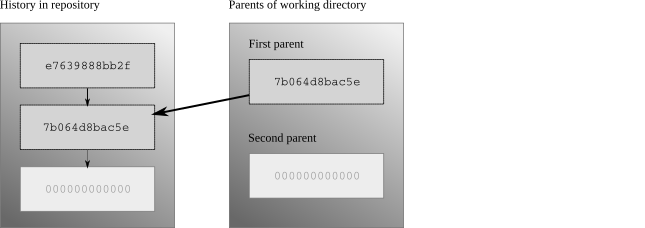
The working directory, updated to an older changeset
Having updated the working directory to an older changeset, what happens if you make some changes, and then commit? Mercurial behaves in the same way as I outlined above. The parents of the working directory become the parents of the new changeset. This new changeset has no children, so it becomes the new tip. And the repository now contains two changesets that have no children; we call these heads. You can see the structure that this creates in fig:concepts:wdir-branch.
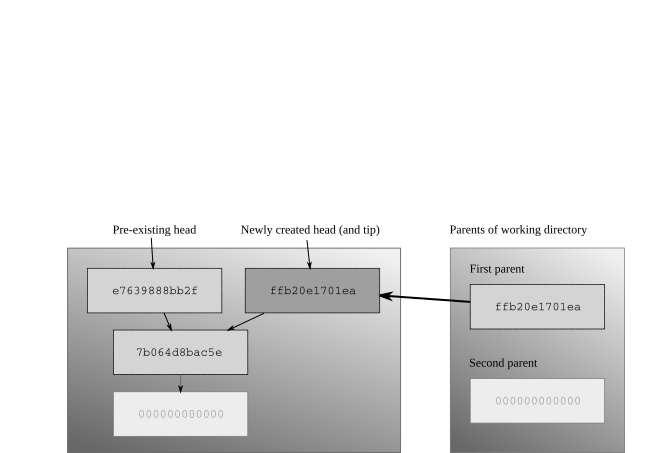
After a commit made while synced to an older changeset
Note
If you're new to Mercurial, you should keep in mind a common “error”, which is to use the hg pull command without any options. By default, the
hg pull command does not update the working directory, so you'll bring new changesets into your repository, but the working directory
will stay synced at the same changeset as before the pull. If you make some changes and commit afterwards, you'll thus create a new head, because
your working directory isn't synced to whatever the current tip is. To combine the operation of a pull, followed by an update, run hg pull -u.
I put the word “error” in quotes because all that you need to do to rectify the situation where you created a new head by accident is
hg merge, then hg commit. In other words, this almost never has negative consequences; it's just something of a surprise for newcomers.
I'll discuss other ways to avoid this behavior, and why Mercurial behaves in this initially surprising way, later on.
Merging changes¶
When you run the hg merge command, Mercurial leaves the first parent of the working directory unchanged, and sets the second parent to the changeset you're
merging with, as shown in fig:concepts:wdir-merge.
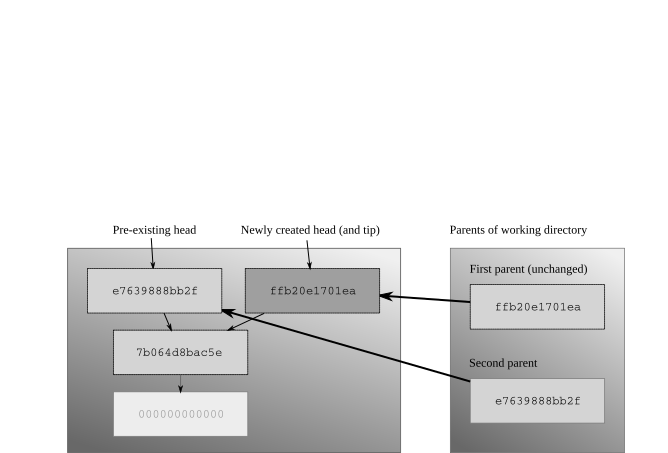
Merging two heads
Mercurial also has to modify the working directory, to merge the files managed in the two changesets. Simplified a little, the merging process goes like this, for every file in the manifests of both changesets.
- If neither changeset has modified a file, do nothing with that file.
- If one changeset has modified a file, and the other hasn't, create the modified copy of the file in the working directory.
- If one changeset has removed a file, and the other hasn't (or has also deleted it), delete the file from the working directory.
- If one changeset has removed a file, but the other has modified the file, ask the user what to do: keep the modified file, or remove it?
- If both changesets have modified a file, invoke an external merge program to choose the new contents for the merged file. This may require input from the user.
- If one changeset has modified a file, and the other has renamed or copied the file, make sure that the changes follow the new name of the file.
There are more details—merging has plenty of corner cases—but these are the most common choices that are involved in a merge. As you can see, most cases are completely automatic, and indeed most merges finish automatically, without requiring your input to resolve any conflicts.
When you're thinking about what happens when you commit after a merge, once again the working directory is “the changeset I'm about to commit”. After
the hg merge command completes, the working directory has two parents; these will become the parents of the new changeset.
Mercurial lets you perform multiple merges, but you must commit the results of each individual merge as you go. This is necessary because Mercurial only tracks two parents for both revisions and the working directory. While it would be technically feasible to merge multiple changesets at once, Mercurial avoids this for simplicity. With multi-way merges, the risks of user confusion, nasty conflict resolution, and making a terrible mess of a merge would grow intolerable.
Merging and renames¶
A surprising number of revision control systems pay little or no attention to a file's name over time. For instance, it used to be common that if a file got renamed on one side of a merge, the changes from the other side would be silently dropped.
Mercurial records metadata when you tell it to perform a rename or copy. It uses this metadata during a merge to do the right thing in the case of a merge. For instance, if I rename a file, and you edit it without renaming it, when we merge our work the file will be renamed and have your edits applied.
Other interesting design features¶
In the sections above, I've tried to highlight some of the most important aspects of Mercurial's design, to illustrate that it pays careful attention to reliability and performance. However, the attention to detail doesn't stop there. There are a number of other aspects of Mercurial's construction that I personally find interesting. I'll detail a few of them here, separate from the “big ticket” items above, so that if you're interested, you can gain a better idea of the amount of thinking that goes into a well-designed system.
Clever compression¶
When appropriate, Mercurial will store both snapshots and deltas in compressed form. It does this by always trying to compress a snapshot or delta, but only storing the compressed version if it's smaller than the uncompressed version.
This means that Mercurial does “the right thing” when storing a file whose native form is compressed, such as a zip archive or a JPEG image. When
these types of files are compressed a second time, the resulting file is usually bigger than the once-compressed form, and so Mercurial will store the
plain zip or JPEG.
Deltas between revisions of a compressed file are usually larger than snapshots of the file, and Mercurial again does “the right thing” in these cases. It finds that such a delta exceeds the threshold at which it should store a complete snapshot of the file, so it stores the snapshot, again saving space compared to a naive delta-only approach.
Network recompression¶
When storing revisions on disk, Mercurial uses the “deflate” compression algorithm (the same one used by the popular zip archive format), which
balances good speed with a respectable compression ratio. However, when transmitting revision data over a network connection, Mercurial uncompresses
the compressed revision data.
If the connection is over HTTP, Mercurial recompresses the entire stream of data using a compression algorithm that gives a better compression ratio
(the Burrows-Wheeler algorithm from the widely used bzip2 compression package). This combination of algorithm and compression of the entire stream
(instead of a revision at a time) substantially reduces the number of bytes to be transferred, yielding better network performance over most kinds of
network.
If the connection is over ssh, Mercurial doesn't recompress the stream, because ssh can already do this itself. You can tell Mercurial to
always use ssh's compression feature by editing the .hgrc file in your home directory as follows.
[ui]
ssh = ssh -C
Read/write ordering and atomicity¶
Appending to files isn't the whole story when it comes to guaranteeing that a reader won't see a partial write. If you recall fig:concepts:metadata, revisions in the changelog point to revisions in the manifest, and revisions in the manifest point to revisions in filelogs. This hierarchy is deliberate.
A writer starts a transaction by writing filelog and manifest data, and doesn't write any changelog data until those are finished. A reader starts by reading changelog data, then manifest data, followed by filelog data.
Since the writer has always finished writing filelog and manifest data before it writes to the changelog, a reader will never read a pointer to a partially written manifest revision from the changelog, and it will never read a pointer to a partially written filelog revision from the manifest.
Concurrent access¶
The read/write ordering and atomicity guarantees mean that Mercurial never needs to lock a repository when it's reading data, even if the repository is being written to while the read is occurring. This has a big effect on scalability; you can have an arbitrary number of Mercurial processes safely reading data from a repository all at once, no matter whether it's being written to or not.
The lockless nature of reading means that if you're sharing a repository on a multi-user system, you don't need to grant other local users permission to write to your repository in order for them to be able to clone it or pull changes from it; they only need read permission. (This is not a common feature among revision control systems, so don't take it for granted! Most require readers to be able to lock a repository to access it safely, and this requires write permission on at least one directory, which of course makes for all kinds of nasty and annoying security and administrative problems.)
Mercurial uses locks to ensure that only one process can write to a repository at a time (the locking mechanism is safe even over filesystems that are notoriously hostile to locking, such as NFS). If a repository is locked, a writer will wait for a while to retry if the repository becomes unlocked, but if the repository remains locked for too long, the process attempting to write will time out after a while. This means that your daily automated scripts won't get stuck forever and pile up if a system crashes unnoticed, for example. (Yes, the timeout is configurable, from zero to infinity.)
Safe dirstate access¶
As with revision data, Mercurial doesn't take a lock to read the dirstate file; it does acquire a lock to write it. To avoid the possibility of
reading a partially written copy of the dirstate file, Mercurial writes to a file with a unique name in the same directory as the dirstate file, then
renames the temporary file atomically to dirstate. The file named dirstate is thus guaranteed to be complete, not partially written.
Avoiding seeks¶
Critical to Mercurial's performance is the avoidance of seeks of the disk head, since any seek is far more expensive than even a comparatively large read operation.
This is why, for example, the dirstate is stored in a single file. If there were a dirstate file per directory that Mercurial tracked, the disk would seek once per directory. Instead, Mercurial reads the entire single dirstate file in one step.
Mercurial also uses a “copy on write” scheme when cloning a repository on local storage. Instead of copying every revlog file from the old repository into the new repository, it makes a “hard link”, which is a shorthand way to say “these two names point to the same file”. When Mercurial is about to write to one of a revlog's files, it checks to see if the number of names pointing at the file is greater than one. If it is, more than one repository is using the file, so Mercurial makes a new copy of the file that is private to this repository.
A few revision control developers have pointed out that this idea of making a complete private copy of a file is not very efficient in its use of storage. While this is true, storage is cheap, and this method gives the highest performance while deferring most book-keeping to the operating system. An alternative scheme would most likely reduce performance and increase the complexity of the software, but speed and simplicity are key to the “feel” of day-to-day use.
Other contents of the dirstate¶
Because Mercurial doesn't force you to tell it when you're modifying a file, it uses the dirstate to store some extra information so it can determine efficiently whether you have modified a file. For each file in the working directory, it stores the time that it last modified the file itself, and the size of the file at that time.
When you explicitly hg add, hg remove, hg rename or hg copy files, Mercurial updates the dirstate so that it knows what to do with those files when you
commit.
The dirstate helps Mercurial to efficiently check the status of files in a repository.
- When Mercurial checks the state of a file in the working directory, it first checks a file's modification time against the time in the dirstate that records when Mercurial last wrote the file. If the last modified time is the same as the time when Mercurial wrote the file, the file must not have been modified, so Mercurial does not need to check any further.
- If the file's size has changed, the file must have been modified. If the modification time has changed, but the size has not, only then does Mercurial need to actually read the contents of the file to see if it has changed.
Storing the modification time and size dramatically reduces the number of read operations that Mercurial needs to perform when we run commands like
hg status. This results in large performance improvements.
| [1] | It is possible (though unusual) for the manifest to remain the same between two changesets, in which case the changelog entries for those changesets will point to the same revision of the manifest. |